Сравнение производительности ms sql server и postgresql. Выбрать субд между mysql, postgresql, mariadb и mssql? История развития MySQL и PostgreSQL
Трудно найти организацию, в которой не используются бухгалтерские системы от 1С – даже в мегахолдингах, где давно внедрён SAP или OEBS, они почти всегда используются на том или ином участке. Отрадно, что российское прикладное ПО стало фактическим стандартом для наших компаний, но есть одна тонкость: столь же фактическим стандартом для самого 1C:Предприятия стало использование Microsoft SQL Server в качестве СУБД.
В среде практикующих 1С-ников наиболее распространено мнение, что без коммерческих СУБД от американских производителей ничего хорошего не выйдет, дескать, несколько сотен пользователей неизбежно требуют установки базы на MS SQL, Oracle Database или IBM DB2 в этом случае. Про работу под управлением свободой СУБД PostgreSQL известные нам мнения практиков расходились, но в диапазоне от «совсем не работает» до «пригодно для нескольких десятков пользователей, не более».
Был и ряд правдоподобных объяснений столь скромным оценкам: и активное использование платформами 1С механизмов временных таблиц (которые в Постгресе реализованы слишком «честно» – с транзакционным DDL, всеми возможностями по восстановлению), и особенности работы с текстовыми данными (тогда как в области многоязычных текстов ванильный Постгрес, опять же, слишком консервативен, используя не самые высокопроизводительные системные библиотеки), и ряд других менее значимых аспектов.
Но мы тайно верили в Постгрес, тем более, что в сборке заявлялось о решении всех тех проблем, которыми скептики оправдывали выбор коммерческих СУБД. К тому же нам было важно получить показатели назначения для аппаратно-программного комплекса – построенной на основе санкционно безопасного оборудования и софта машины баз данных для СУБД, разработанной IBS совместно с Postgres Professional.
Из тиражируемых приложений самым очевидным применением для такой машины должны стать, конечно же, системы 1C. И результаты проведённых бенчмарков полностью перевели нас из разряда «тайно верующих» (и даже сомневающихся) в категорию «убеждённых»: теперь мы можем смело утверждать, что 1C:Предприятие версии 8.3 на сборке Postgres Pro EE 1.5 для Скалы-СР / Postgres Pro работает лучше, чем на MS SQL 2012 на том же оборудовании со всеми возможными оптимизациями.
Итак, некоторые детали экспериментов. В плане тестирования производительности у 1С всё системно и научно – есть типовая конфигурация «Стандартный нагрузочный тест », на которой и запускается бенчмарк, поэтапно добавляющий новых пользователей в нагрузку до тех пор, пока приложение работает достаточно отзывчиво для комфортной работы. (Более точно – пользователи добавляются до тех пор, пока стандартный показатель производительности приложений Apdex не опускается ниже порога в 0,85, и максимальное число таких эффективно работающих пользователей и считается результатом бенчмарка.)
Мы использовали версию 8.3.9.1850 1С:Предприятия, стандартный нагрузочный тест в версии 2.0.17.36. Изначально было решено никаких скидок Постгресу не давать: делаем максимальные оптимизации на MS SQL на узле из комплекса Скала-СР / Postgres Pro (ставим Windows на «голое железо», настраиваем по всем канонам , для скорости – делаем ramdisk для временных таблиц), а потом – возвращаем тот же узел в комплекс Скала-СР, накатываем Linux и Postgres Pro EE, и на нём одном (без доступных в комплексе кластерных фишек) – прогоняем тот же тест.
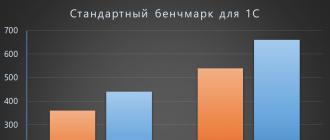
Тест первый: начинаем со 100 рабочих мест, нагрузка 50/50 – половина формирует документы, половина – отчёты. Тест второй: начинаем с 400, нагрузка 70/30. MS SQL «закончился» в первом тесте на 360 пользователях, на втором – на 540, притом ограничителем в обоих пусках стала работа с локальным вводом-выводом, при том, что загрузить процессор удалось в среднем лишь на 30%. Postgres Pro в первом тесте дошёл до 440 рабочих мест, а на втором – до 660, а упёрлось на сервере БД всё в процессор, уходящий в загрузку более 90% на «максимальных пользователях».
Для 1С, где количество одновременно работающих пользователей – самый проблемный ограничивающий фактор, это замечательный результат, а главное, говорящий о том, что эти важнейшие российские прикладные системы могут не просто функционировать и без западных коммерческих СУБД, но даже делать это заметно лучше. 
И сейчас встал выбор СУБД для хранения основных данных. Начинал разработку на MySQL, но сейчас не уверен в выборе. Переезд на другую СУБД на данном этапе для меня не составит проблем (использую PDO). далек от ясного понимания что такое «высокие нагрузки» для СУБД. Просто по моим расчетам примерно через год база будет весьма увесистой (см. ниже)
Основной выбор стоит между MySQL, PostgreSQL, MariaDB. Также, возможен, но не приветствуется вариант Microsoft SQL Server на Windows Azure
Ситуация такова:
- Сложных запросов к базе нет. Максимум JOIN из двух таблиц
- Бо льшая часть запросов - чтение
- Есть одна самая важная и «главная» таблица (структура таблицы ниже под спойлером). Таблица будет расти примерно на 10-30 тысяч записей в сутки. Запись данных в эту таблицу - самое главное!
- Бо льшая часть запросов на чтение будет как раз к «главной» таблице. По этой таблице будет осуществляться поиск по любому из полей (в крайне редких случаях ~0.5% - по нескольким сразу). Поиск должен осуществляться быстро (не смотря на пункт №3)
- К «главной» таблице скорее всего будут добавлены индексы к каждому из полей сразу для двух полей (ownerID и Имя поля т.к. ownerID будет указан во всех запросах). Быстрый поиск будет нужен по любому из полей, но это не столь приоритетная задача. (Или лучше использовать Sphinx?)
- Львиная доля запросов (~80%) на чтение к «главной» таблице - простые select"ы по индексам from и personalID с limit = 20. Остальные запросы по любым другим полям по индексам (которых пока нет) ownerID и Имя поля, также с limit = 20
- Изменения данных в записях «главной» таблицы будут происходить крайне редко. Никакие записи из таблицы удаляться не будут.
- Поддержка транзакций и внешних ключей не обязательна
- Нужна возможность репликации данных типа master-slave
- Возможность шардинга на уровне СУБД приветствуется
- Крайне важна надежность БД (т.е. такой крах, как у MyISAM с ручным восстановлением сразу отпадает)
- К «главной» таблице могут добавляться новые поля. Это конечно крайне редкое явление и далеко не самое важное требование, но добавление нового столбца к таблице размером с десяток ГБ для MySQL весьма длительный процесс, а выносить новые поля в отдельную таблицу очень не хочется
- Всё это по-началу будет крутиться на таком вот выделенном сервере
- Другие таблицы будут расти медленно, и обращения к ним будут достаточно редкими, за них я не переживаю. Часто обновляемые данные у меня крутятся в redis"e
P.S. Желающих отправить меня гуглить прошу даже не отвечать. Найти информацию по сравнению актуальных версий разных СУБД мне не удалось, а изучать возможности, плюсы и минусы PostgreSQL, Microsoft SQL Server и MariaDB для человека, который с ними не работал весьма долгая задача. Да и в MySQL я далеко не эксперт, и подобный крупный проект для меня дело новое, да и возможности MySQL от версии к версии отличаются. Единственное, что я точно знаю, так это то, что таблицы типа MyISAM в MySQL мне точно не подойдут
- Вопрос задан более трёх лет назад
- 39571 просмотр
Давайте признаемся честно, хоть 1С Предприятие и совместимо со многими СУБД, но по факту 99 процентов работают либо в MS SQL или в бесплатной PostgreSQL.
Другими словами эти две «субдешки» завоевали рынок клиент-серверной 1С.
И можно смело предполагать, что если компания не работает в MS SQL то, скорее всего, просто используют PostgreSQL.
Соответственно сравнивать «Постгрес» есть смысл разве что только с MS SQL.
Сегодня много пишут, как об MS SQL так и о PostgreSQL, но обычно объективно не сравнивают их.
В этой статье мы же разберем основные технические моменты бесплатной PostgreSQL, сравнивая ее c MS SQL.
Что позволит Вам в будущем сделать оптимальный выбор и быть готовым к разным «неожиданностям» или что будет более правильно «особенностям» работы в этой бесплатной СУБД.
Оценивать будем все как есть, не приплюсовуя Постгресу тех заслуг, которых у него нет и, не приукрашивая платный MS.
Сразу отвечу на вопрос, который волнует многих новичков!
ДА! MS SQL работает быстрее PostgreSQL, это факт! И на это есть ряд причин!
Возможно, я кого-то прямо сразу разочаровал, и возможно, Вы не согласны с таким утверждением, извиняюсь, но сама физика работы этой бесплатной СУБД не позволяет ему опередить MS SQL, особенно если мы говорим о такой связке как «Монстр 1С» и PostgreSQL .
Подобные доводы Вы не раз встретите на различных конференциях и семинарах посвященных этой СУБД. Никто ничего не скрывает и не отрицает, факт есть факт.
Тем не менее, производительности PostgreSQL вполне достаточно, для того, чтоб пользователи могли комфортно работать в 1С.
Будь это десяток пользователей или даже несколько сотен, одновременно работающих в 1С Предприятии.
Почему «Монстр 1С» ?
Собственно так 1С видит PostgreSQL без установленных специальных «патчей» и расширений.
Да, что называется из коробки, скачав дистрибутив PostgreSQL на оф. сайте Вы не сможете использовать его для работы в связке с 1С. 1С-ка будет жутко тормозить и просто останавливаться, отказываться работать.
Почему так происходит, и зачем «патчи»?
Дело в том что 1С Предприятие создает огромное количество временных таблиц в процессе своей работы, речь может идти о тысячах таблиц в секунду, а если взять, например регистр «Срез последних» — «ОстаткиИОбороты», там вполне могут и по миллиону строк быть.
Дело в том что по умолчанию (без «патчей») PostgreSQL не считает статистику по этим большим временным таблицам, другими словами оптимизатор запросов который руководствуется данными из статистики (а она как помним пуста, нечего считать) грубо говоря, делает выборку методом SELECT * что конечно будет работать очень и очень медленно!
Отсюда грандиозные тормоза в 1С!
Конечно это не все проблемы, которые нужно решить, чтоб PostgreSQL работал в паре с 1С нормально. Нужны будут и другие «патчи» и специальные расширения и после 15-20 пользователей, еще и доп. настройки в «конфиге»
Да, на самом деле в реалии все выглядит намного сложнее, чем я описал выше, но вот так если сильно упростить и будет выглядеть основная проблема медленной работы 1С с PostgreSQL.
Второе что мне сильно не нравится в PostgreSQL это отсутствие многопоточности в рамках одного запроса в сравнении с MS SQL.

(Начиная с версии 9.6 сделали первую попытку распараллеливания запросов, но пока работает плохо, иногда эффект обратный). но за попытку 5!)
Что конечно влияет на производительность, чтоб Вы понимали простым языком —
PostgreSQL способен уложить Ваш 48-ми ядерный сервер, одним большим запросом!

Все просто, распараллеливания потоков в рамках одного запроса нет и один большой запрос «грузит» только одно ядро.
Да, если запросов много, тогда все ядра будут нагружены, и все будет работать хорошо.

И чуть не забыл, сравниваем мы PostgreSQL c MS SQL Standard не Express!
Express хоть и можно использовать в коммерческих целях, но целый ряд ограничений
таких как 10 Гб на базу, использование одного процесора, 1 Гб оперативной памяти,
делает использование такого продукта почти нереальным для работы в 1С Предприятии.
Разве что у вас очень маленькая база и всего пара пользователей, (да и то бывают тормоза 1 гб для СУБД очень мало).
Так что сравниваем PostgreSQL с популярной версией Standard.
СКРИПТЫ!!!
PostgreSQL это прежде всего скрипты в сравнении с MS SQL, большинство операций приходится делать руками, да можно установить конечно и некоторые базовые вещи выполнять через интерфейс, но подчеркну, что базовые , а шаг влево шаг вправо и нужно писать скрипт, или БАШ на Линуксе или cmd, powershell наWindows.

Просмотр и анализ трассировок с помощью приложения SQL Server Profiler.
Всем известный SQL Server Profiler в PostgreSQL отсутствует, причем под словом «отсутствует» я имею, введу напрочь, увы, нет ничего подобного в PostgreSQL.

Есть, конечно, утилиты, которые позволяют, если успеть перехватить запрос или поставить точку останова 1С в отладчике и что-то получит и посмотреть, но в сравнении с Профайлером как говорится и близко не стояло.
Можно настроить лог и потом это все перебирать — но долго!
Вот пример:
Программист 1С пытается отладить какой-нибудь большой запрос, он долго выполняется, например 30 минут, так вот в PostgreSQL, чтоб данные попали в лог, этот запрос должен выполнится! Представляете, как долго можно отлаживать такой запрос?
В то время как в MS SQL можно прервать выполнение запроса и в Профайлере его разобрать, так как он там уже будет, но со статусом «failed».
По разновидности создания «бэкапов» Постгресу нет равных!
Здесь Вам и инкрементный «бекап» и полное резервное копирование и непрерывное WAL архивирование.
Как собственно есть и частичное резервное копирование и частичное восстановление данных.

Можно настроить непрерывное архивирование и восстановление на момент времени (Point-in-Time Recovery (PITR)) .
Также репликация , доступна изначально в PostgreSQl без каких либо «патчей» утилит и дополнений!
- Каскадная репликация
- Потоковая репликация
- Синхронная репликация
- Непрерывное архивирование на резервном сервере
Все это есть, уже изначально в PostgreSQl и конечно нет в «экспрессе» и недоступно на версии MS SQL Standard.
Чтоб получить все выше перечисленное в MS SQL, нужно покупать очень дорогой MS SQL Enterprise, сейчас что-то около 15 000$ долларов.
Чего нет в сравнении с MS SQL ?
НЕТ диференциального «бэкапа»
Да в PostgreSQl нет дифференциального «бэкапа», но есть различные аналоги инкрементного создания «бэкапов».
Например, инкрементный «бэкап» на уровне блоков.
ЕСТЬ разделение TABLESPACE-ов, что уже по умолчанию поддерживает 1С!
Которого к слову нет в MS SQL!

Например, Вы можете настроить на каком диске у вас будут «индексы» и на каком диске будет находиться «таблица», очень удобно при планировании IТ инфраструктуры, когда речь идет о больших базах данных 1С. ONLINE_ANALYZE , чтоб пересчитать статистику. Тоже самое касается файла *dt.
Используя PostgreSQl очень редко нужен REINDEX!
Фактически стоит использовать только когда, есть подозрения, что целостность базы данных повреждена.

Можно делать «бэкапы» с исключением таблиц!
Например, у вас в компании работают несколько программистов 1С, они гарантированно будут делать себе резервные копии создавать «бэкапы» для дальнейшей разработки.
В итоге страдают пользователи, база тормозит во время создания большого «бэкапа» особенно если в этой базе есть такие вещи как различные прикрепленные файлы, архивы, документы из писем. Такие таблицы с файлами запросто могут содержать сотни гигабайт. И их же можно исключить в PostgreSQl создавая «бэкап», тем самым малого размера, и со всем функционалом одновременно.

Так мы лишний раз не нагружаем сетевые устройства, не забиваем канал, тратим намного меньше времени на создание такого «бэкапа»
В итоге все в выигрыше! И пользователи, и программисты и админы спят спокойно.
В этой статье мы разобрали лишь базовые отличия PostgreSQl от MS SQL, (есть и другие) но определится с выбором в пользу той или иной СУБД, статья должна помочь!
Успехов Коллега!
P.S. Сейчас работаю над новым курсом «1С и PostgreSQL» (Уже на стадии записи, ждите, скоро!)
С уважением, Богдан.
Серия контента:
1. История развития MySQL и PostgreSQL
История MySQL начинается в 1979 г., у ее истоков стояла небольшая компания во главе с Monty Widenius. В 1996 г. появился первый релиз 3.11 под солярис с публичной лицензией. Затем MySQL была портирована под другие операционные системы, появилась специальная коммерческая лицензия. В 2000 г., после добавления интерфейса, аналогичного Berkeley DB, база стала транзакционной. Примерно тогда же была добавлена репликация. В 2001 г. в версии 4.0 был добавлен движок InnoDB к уже имеющемуся MyISAM, в результате чего появилось кеширование и возросла производительность. В 2004 г. вышла версия 4.1, в которой появились подзапросы, парциальная индексация для MyISAM, юникод. В версии 5.0 в 2005 г. появились хранимые процедуры, курсоры, триггеры, представления (views). В MySQL развиваются коммерческие тенденции: в 2009 г. MySQL стала торговой маркой компании Oracle.
История постгрес началась в 1977 г. с базы данных Ingress.
В 1986 г. в университете Беркли, Калифорния, она была переименована в PostgreSQL.
В 1995 г. постгрес стала открытой базой данных. Появился интерактивный psql.
В 1996 г. Postgres95 была переименована в PostgreSQL версии 6.0.
У постгреса несколько сотен разработчиков по всему миру.
2. Архитектура MySQL и PostgreSQL
PostgreSQL – унифицированный сервер баз данных, имеющий единый движок – storage engine. Постгрес использует клиент-серверную модель.
Для каждого клиента на сервере создается новый процесс (не поток!). Для работы с такими клиентскими процессами сервер использует семафоры.
Клиентский запрос проходит следующие стадии.
- Коннект.
- Парсинг: проверяется корректность запроса и создается дерево запроса (query tree). В основу парсера положены базовые юниксовые утилиты yacc и lex.
- Rewrite: берется дерево запросов и проверяется наличие в нем правил (rules), которые лежат в системных каталогах. Всякий раз пользовательский запрос переписывается на запрос, получающий доступ к таблицам базы данных.
- Оптимизатор: на каждый запрос создается план запроса – query plan, который передается исполнителю – executor. Смысл плана в том, что в нем перебираются все возможные варианты получения результата (использовать ли индексы, джойны и т.д.), и выбирается самый быстрый вариант.
- Выполнение запроса: исполнитель рекурсивно проходит по дереву и получает результат, используя при этом сортировку, джойны и т.д., и возвращает строки. Постгрес – обьектно-реляционная база данных, каждая таблица в ней представляет класс, между таблицами реализовано наследование. Реализованы стандарты SQL92 и SQL99.
Транзакционная модель построена на основе так называемого multi-version concurrency control (MVCC), что дает максимальную производительность. Ссылочная целостность обеспечена наличием первичных и вторичных ключей.
MySQL имеет два слоя – внешний слой sql и внутренний набор движков, из которых наиболее часто используется движок InnoDb, как наиболее полно поддерживающий ACID.
Реализован стандарт SQL92.
С модульной точки зрения код MySQL можно разделить на следующие модули.
- Инициализация сервера.
- Менеджер коннектов.
- Менеджер потоков.
- Обработчик команд.
- Аутентификация.
- Парсер.
- Оптимизатор.
- Табличный менеджер.
- Движки (MyISAM, InnoDB, MEMORY, Berkeley DB).
- Логирование.
- Репликация.
- Сетевое API.
- API ядра.
Порядок работы модулей следующий: сначала загружается первый модуль, который читает опции командной строки, конфиг-файлы, выделяет память, инициализирует глобальные структуры, загружает системные таблицы и передает управление менеджеру коннектов.
Когда клиент подсоединяется к базе, управление передается менеджеру потоков, который создает поток (не процесс!) для клиента, и проверяется его аутентификация.
Клиентские запросы в зависимости от их типа на верхнем уровне обрабатываются четвертым модулем (dispatcher). Запросы будут залогированы 11-м модулем. Команда передается парсеру, проверяется кеш. Далее запрос может попасть в оптимизатор, табличный модуль, модуль репликации, и т.д. В результате данные возвращаются клиенту через менеджер потоков.
Наиболее важный код находится в файле sql/mysqld.cc. В нем находятся базовые функции, которые не меняются со времен версии 3.22: init_common_variables() init_thread_environment() init_server_components() grant_init() // sql/sql_acl.cc init_slave() // sql/slave.cc get_options() handle_connections_sockets() create_new_thread() handle_one_connection() check_connection() acl_check_host() // sql/sql_acl.cc create_random_string() // sql/password.cc check_user() // sql/sql_parse.cc mysql_parse() // sql/sql_parse.cc dispatch_command() Query_cache::store_query() // sql/sql_cache.cc JOIN::optimize() // sql/sql_select.cc open_table() // sql/sql_base.cc mysql_update() // sql/sql_update.cc mysql_check_table() // sql/sql_table.cc
В хидере sql/sql_class.h определяются базовые классы: Query_arena, Statement, Security_context, Open_tables_state classes, THD. Обьект класса THD представляет собой дескриптор потока и является аргументом большого количества функций.
3. Сравнение MySQL и PostgreSQL: сходство и различия
ACID-стандарт
Стандарт ACID базируется на атомарности, целостности, изоляции и надежности. Эта модель используется для гарантии целостности данных. Реализуется это на основе транзакций. PostgreSQL полностью соответствует стандарту ACID. Для полной поддержки ACID в MySQL в конфиге нужно установить default-storage-engine=innodb.
Производительность (performance)
Базы данных часто оптимизируются в зависимости от окружения, в котором они работают. Обе базы имеют различные технологии для улучшения производительности. Исторически так сложилось, что MySQL начинала разрабатываться с прицелом на скорость, а PostgreSQL с самого начала разрабатывалась как база с большим числом настроек и соответствием стандарту. PostgreSQL имеет ряд настроек, которые повышают скорость доступа:
- парциальные индексы;
- компрессия данных;
- выделение памяти;
- улучшенный кеш.
MySQL имеет частичную поддержку парциальных индексов в InnoDB. Если взять MySQL-ский движок ISAM, он оказывается быстрее на плоских запросах, при этом нет блокировок на инсерты, нет поддержки транзакций, foreign key.
Компрессия
PostgreSQL лучше сжимает и разжимает данные, позволяя сохранить больше данных на дисковом пространстве. При этом компрессионные данные читаются быстрее с диска.
MySQL-компрессия для разных движков частично поддерживается, частично нет, и это зависит от конкретной версии конкретного движка.
На мульти-процессорности PostgreSQL имеет преимущество над MySQL. Даже сами разработчики MySQL признают, что их движок в этом плане не так хорош.
Типы данных
MySQL: для хранения бинарных данных использует типы TINYBLOB, BLOB, MEDIUMBLOB, LONGBLOB, которые отличаются размером (до 4 ГБ).
Character: четыре типа – TINYTEXT, TEXT, MEDIUMTEXT, LONGTEXT.
PostgreSQL: поддерживает механизм пользовательских данных с помощью команды CREATE TYPE, тип BOOLEAN, геометрические типы.
Character: TEXT (ограничение – max row size).
Для хранения бинарных данных есть тип BLOB, который хранится в файловой системе. Столбцы таблицы могут быть определены как многомерный массив переменной длины. Обьектно-реляционное расширение: структура таблицы может быть унаследована от другой таблицы.
Хранимые процедуры
И PostgreSQL , и MySQL поддерживают хранимые процедуры. PostgreSQL придерживается стандарта Oracle PL/SQL, MySQL – IBM DB2. MySQL поддерживает extend SQL для написания функций на языке C/C++ с версии 5.1. PostgreSQL: PL/PGSQL, PL/TCL, PL/Perl, SQL, C для написания хранимых процедур.
Ключи
И PostgreSQL , и MySQL поддерживают уникальность Primary Key и Foreign Key. MySQL не поддерживает check constraint плюс вторичные ключи реализованы частично. PostgreSQL: полная реализация плюс поддержка ON DELETE CASCADE и ON UPDATE CASCADE.
Триггеры
MySQL: рудиментарная поддержка. PostgreSQL: декларативные триггеры: SELECT, INSERT, DELETE, UPDATE, INSTEAD OF; процедурные триггеры: CONSTRAINT TRIGGER. События: BEFORE или AFTER на INSERT, DELETE , UPDATE.
Автоинкремент
MySQL: в таблице может быть только один такой столбец, который должен быть проиндексирован. PostgreSQL: SERIAL data type.
Репликации
Поддерживаются и в MySQL, и в PostgreSQL. PostgreSQL имеет модульную архитектуру, и репликация входит в отдельные модули:
- Slony-I – основной механизм репликации в постгресе, производительность падает в квадратичной зависимости от числа серверов;
Репликация в PostgreSQL основана на триггерах и более медленная, чем в MySQL. В ядро репликацию планируется добавить, начиная с версии 8.4.
В MySQL репликация входит в ядро и имеет две разновидности, начиная с версии 5.1:
- SBR – statement based replication;
- RBR – row based replication.
Первый тип основан на логировании записей в бинарный лог, второй – на логировании изменений. Начиная с версии 5.5, в MySQL поддерживается так называемая полусинхронная репликация, при которой основной сервер (master) делает сброс данных на другой сервер (slave) при каждом коммите. Движок NDB делает полную синхронную двухфазную репликацию.
Транзакции
MySQL: только для для InnoDB. Поддержка SAVEPOINT, ROLLBACK TO SAVEPOINT. Уровни блокировки: table level (MyISAM). PostgreSQL: поддерживается плюс read committed и уровни изоляции. Поддержка ROLLBACK, ROLLBACK TO SAVEPOINT. Уровни блокировки: row level, table level.
Уровни привилегий
PostgreSQL: для пользователя или группы пользователей могут быть назначены привилегии.
Экспорт-импорт данных
MySQL: набор утилит для экспорта: mysqldump, mysqlhotcopy, mysqlsnapshot. Импорт из текстовых файлов, html, dbf. PostgreSQL: экспорт – утилита pg_dump. Импорт между базами данных и файловой системой.
Вложенные запросы
Есть и в MySQL, и в PostgreSQL, но в MySQL могут работать непроизводительно.
Индексация
Хэширование индексов: в MySQL– частичное, в PostgreSQL – полное. Полнотекстовый поиск: в MySQL– частичный, в PostgreSQL – полный. Парциальные индексы: в MySQL не поддерживаются, в PostgreSQL поддерживаются. Многостолбцовые индексы: в MySQL ограничение 16 столбцов, в PostgreSQL – 32. Expression-индексы: в MySQL– эмуляция, в PostgreSQL – полное. Неблокирующий create index: в MySQL – частичное, в PostgreSQL – полное.
Партиционирование (Partitioning)
MySQL поддерживает горизонтальное партиционирование: range, list, hash, key, композитное партиционирование. PostgreSQL поддерживает RANGE и LIST. Автоматическое партиционирование для таблиц и индексов.
Автоматическое восстановление после сбоев
MySQL: частичное для InnoDB – нужно вручную сделать backup. PostgreSQL: Write Ahead Logging (WAL).
Data Storage Engines
PostgreSQL поддерживает один движок – Postgres Storage System. В MySQL 5.1 их несколько:
- MyISAM – используется для хранения системных таблиц;
- InnoDB – максимальное соответствие ACID, хранит данные с первичными ключами, кэширует инсерты, поддерживает компрессию, начиная с версии 5.1 – см. атрибут ROW_FORMAT=COMPRESSED;
- NDB Cluster – движок, ориентированный на работу с памятью, кластерная архитектура, использующая синхронную репликацию;
- ARCHIVE – поддерживает компрессию, не использует индексы;
- а также: MERGE, MEMORY (HEAP), CSV.
InnoDB разрабатывается компанией InnoBase, являющейся дочерней компанией Oracle. В 6-й версии должны появиться два движка – Maria и Falcon. Falcon – движок, основанный на ACID-транзакциях.
Лицензирование
PostgreSQL: BSD (Berkeley Software Distribution) open source. MySQL: GPL (Gnu General Public License) или Commercial. MySQL – это open-source продукт. Postgres – это open-source проект.
Заключение
Подводя итоги, можно сказать следующее: MySQL и PostgreSQL – две наиболее популярные open-source базы данных в мире. Каждая база имеет свои особенности и отличия. Если вам нужно быстрое хранилище для простых запросов с минимальной настройкой, я бы порекомендовал MySQL. Если вам нужно надежное хранилище для большого объема данных с возможностью расширения, репликации, полностью соответствующее современным стандартам языка SQL, я бы предложил использовать PostgreSQL.
Мы обсудим вопросы настройки MySQL и PostgreSQL.
Ресурсы для скачивания
static.content.url=http://www.сайт/developerworks/js/artrating/
Zone=Open source, Linux
ArticleID=779830
ArticleTitle=MySQL & PostgreSQL: Часть 1. Сравнительный анализ